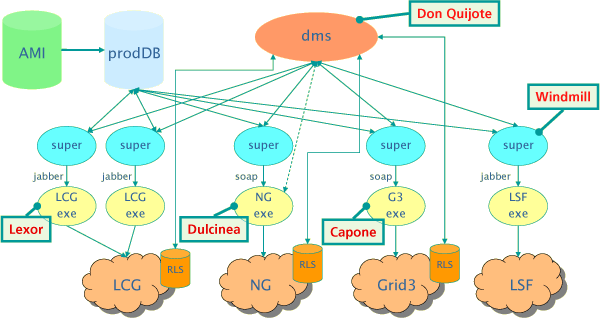
About ATLAS prodsys
The ATLAS prodsys consists of 4 components:
- The production database containing abstract job definitions of all simulations that have to be performed. Uses info from AMI database.
- The Windmilll supervisor that reads the production database for job definitions and present them to the different Grid executors in an easy-to-parse XML format. It also queries the executors for job status' etc. and writes information about finished jobs in the production database.
- Executors – one for each Grid flavor – that
receive the job-definitions in XML format and convert them to
the job description language of that particular Grid. For example, in
case of the Dulcinea
NorduGrid executor the XML job definitions are converted to
XRSL and the corresponding job is submitted. The executors
also answer Windmill's queries about job status etc. The executors are:
- Capone, for Grid3+
- Dulcinea, for NorduGrid ARC
- Lexor, for LCG2
- Legacy Executor, for non-Gridified local resource managers
- Don Quijote – the Atlas Data Management System. This component moves files from their temporary output locations (where they were produced) to their final destination on some Storage Element and registers the files in the Replica Location Service of that Grid.
By design, these 4 components constitute an automatic Atlas production system. The communication between the Windmill and the executors is in XML format and follows an ever-evolving schema. Basically, the supervisor can ask an executor to perform 6 different tasks:
-
numJobWanted
How many jobs does the executor want conforming to certain requirements? Those requirements are: ATLAS release to be used, CPU-time, disk-space, RAM and whether outbound-connectivity is needed or not. -
executeJobs
The supervisor presents the executor with a number of job definitions. These are then translated into job description language format and submitted. For example in the XML schema, there is a field called transUses which matches GlueHostApplicationSoftwareRunTimeEnvironment of LCG (Glue) or runTimeEnvironment of NorduGrid. Similarly there is a list of actualPar's which exactly matches Arguments of LCG's JDL, or arguments of Globus' RSL and NorduGrid's XRSL, and so on. -
getStatus
The supervisor asks for status of jobs which have been submitted. These jobs can in principle be in any state, but the executor has to gather the information about them in some way and send it back to the supervisor. Is the job finished? – if so, has the output data been uploaded? – where is the output data? – how much CPU-time did the job consume? etc. -
killJob
The supervisor asks the executor to kill one or many jobs. -
getExecutorData
The supervisor asks the executor for the submitted jobid from the job name given in executeJobs. -
fixJob
Somebody thought this was nice to have – although nobody ever specified what fixJob meant. So although it's still there, it doesn't really have a fixed meaning.
Technically the executor/supervisor use the Jabber protocol for communication. Unfortunately this does not allow proxy forwarding, so all jobs are run with the proxy of the person controlling the executor. The supervisor is deliberately designed to be unaware of Grid and even of proxies, although it could have been more elegant to have proxy forwarding, since this would allow to deploy one executor server that could receive the job request without having somebody with a proxy watch over it.
The executors also have to take care of some RLS-specfic things:
An ATLAS production job that uses some input files has to have a special file called PoolFileCatalog.xml in the session directory with special information about those files. This special file is created when the input files themselves are created (in some earlier simulations) but the only essential information in it is a GUID (Globally Unique IDentifier). So this GUID has to be stored together with the input files when (during the earlier simulations) these are uploaded and registered in the RLS.
One could of course just store the PoolFileCatalog by itself to avoid such a proliferation of files with that name, the choice has been to store the GUID as an RLS-attribute (called dq_guid) of the input file. The registration of the GUID is then done by the executor.
You can see the GUID's in the RLS-server by querying it. For example:
~$ globus-rls-cli attribute query \
dc2.003102.evgen.A1_z_ee.nordugrid._00070.pool.root.1 dq_guid
\
lfn rls://gridsrv3.nbi.dk dq_guid: \
string: 40C03EE4-D4AF-D811-8528-00304870D4F4
Now to reconstruct the correct PoolFileCatalog.xml before the simulations
using that file as input file, the executor queries the RLS for the
dq_guid attribute of that LFN, passes that as an argument to a
wrapper-script that reconstructs the PoolFileCatalog.xml before the actual
simulations start.