JURA Accounting Technical Details¶
General accounting configuration and operations flows are described in Accounting with JURA. This section contains more technical details about implementation of each component of accounting subsystem.
Records processing and publishing¶
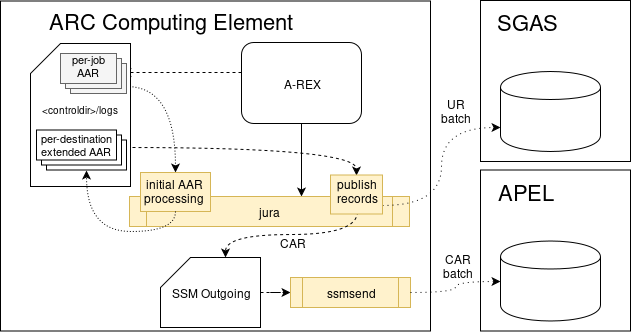
Fig. 20 ARC CE accounting: records creation, processing and publishing
AREX Accounting Records (AAR job log files)¶
The A-REX Accounting Records (AAR) are job log files generated by A-REX.
AAR is the only source of accounting information for JURA.
AARs are written by A-REX based on job data available, including .diag files that backend scripts creates based on batch system data and/or GNU time utility measurements.
These job log files reside under the <control_dir>/logs directory.
The name of the AAR job log files consist of the ID of the job and a random string
to avoid collision of multiple job log files for the same job: <jobid>.<random>.
The AAR job log file consists of name=value lines, where value is either a
job-related resource consumption data or a static info like name, ID or proxy certificate.
A-REX generates at least two job log files for each job: one at the time of job submission, another one
after the job finishes, and possibly others at various job events.
Please note JURA makes use only one of the AREX generated files belonging to the same job:
the one that corresponds to the FINISHED job event (such state is indicated by the status={completed|failed|aborted}).
JURA initial AAR processing¶
A-REX periodically runs jura that loop over available A-REX job log records in the <control_dir>/logs.
JURA opens all the files and processes only those that corresponds to a FINISHED job state.
JURA converts AARs to per-job per-destnation extended AARs that contains the target information
from arc.conf as well. One extended AAR is generated per accounting target.
The extended AAR job log files named <jobid>.<random>_<random2> where first <random> is taken from
original AAR.
The original AAR <jobid>.<random> file is deleted once per-destination extended AAR logs are created by JURA.
Note
JURA as part of the initial processing deletes all files corresponding to non-finished job states.
JURA Publihsing loop¶
JURA publishing subsystem loop over extended AAR logs in the A-REX <control_dir>/logs directory.
JURA generates records in the Usage Record (UR) format proposed by the Open Grid Forum (OGF) for SGAS or
Compute Accounting Record (CAR) XML for APEL.
The extended AAR job log file is deleted once record is successfully submitted, thus preventing multiple insertion of same usage records. If submission to destination fails, the extended AAR log files are kept, so another attempt is made upon a subsequent run of JURA. This mechanism will be repeated until the expiration time passes at which point the next execution of JURA removes the file without processing.
Please note that the JURA publishing loop is backward compatible with ARC 5 implementation.
Reporting to SGAS¶
SGAS has a simple custom web service interface loosely based on WS-ResourceProperties. JURA uses the insertion method of this interface to report URs directly using ARC HTTP client implementation. The corresponding processed extended AAR job log files are deleted after receiving a non-fault response from the service.
To increase communication efficiency JURA sends URs in batches. SGAS accepts a
batch of URs in a single request. The batch is an XML element called
UsageRecords, containing elements representing URs.
The process of handling batches is the following: JURA does not send all usage records immediately after generation, but instead collects them in a batch until reaching the maximal number of records or until running out of job log files. The maximal number of URs in a batch can be set as a urbatchsize configuration parameter of SGAS target.
Reporting to APEL¶
APEL uses the SSM framework for communication.
JURA send records to APEL by means of invoking helper ssmsend process that uses SSM python librarires developed by APEL.
ARC ships minimal set of SSM libraries along with A-REX binary packages to allow SSM usage. If SSM binary packages from APEL are availble for your OS (e.g. EL6), you can install this packages and they will be used instead of those shipped with ARC automatically.
JURA prepares the messages to be sent by ssmsend and puts them info SSM Outgoing directory
located in the /var/spool/arc/ssm/<destination hostname>/outgoing/00000000/.
Generated messages are XML based CAR records with file name format <YYYYMMDDhhmmss>.
Reporting to APEL also works with sending records in batches. The default urbatchsize value is set to 1000 according to APEL recommendatations.
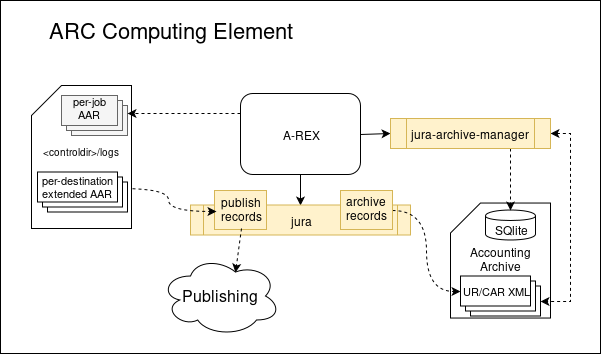
Republishing process¶
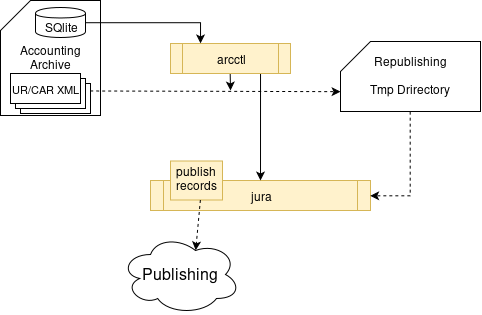
Fig. 22 ARC CE accounting: records republishing
TODO: Describe republishing workflow in bit more details
Security¶
The JURA executable runs with the same user privileges as the A-REX. The owner of a job log file is the local user mapped for the submitter entity of the corresponding job. Since these files contain confidential data, A-REX restricts access to them allowing only read access for the job owner, thus when JURA is executed by A-REX it is allowed to read and delete job log files.
All usage records are submitted using the X.509 credentials specified by
the value of x509_ set of confiurartion options of arc.conf.
No proxies are used for communcation with accouting services.
The only access restriction made by a SGAS service is matching the Distinguished Name of the client (in this context JURA) with a set of trusted DNs. When access is granted, policies are then applied by SGAS, allowing either publishing and/or querying rights. Clients with publishing right can insert any UR, regardless of content. By default, querying right only allows retrieving URs pertaining to jobs submitted by the querying entity.
Implementation and API¶
JURA as part of the ARC software stack is written in C++, and utilizes the functionality provided by the ARC libraries, including secure HTTPS communication provided by the ARC plugable TLS and HTTP modules.
The modular design is also present in the usage reporting part of the
JURA code, making it possible to extend JURAs support of accounting
services. To create a JURA module one should simply write a C++ class
which inherits from the abstract Arc::Destination class, and it must
extend the two methods:
static Arc::Destination* Arc::Destination::createDestination(Arc::JobLogFile&)void Arc::Destination::report(Arc::JobLogFile&)
The static createDestination method should initialize a object of
the specialized class, using the configuration options specified in the
passed Arc::LogFile object, and the memory allocated by the method
should be freed by the caller. Then the report method should carry
out the transfer of the UR, represented by the JobLogfile object, to
the accounting service.
JURA archive manager is written in Python and share the classes for managing ARC components with ARC Control Tool.
Limitations¶
In the following list some issues which limits the functionality of JURA is described:
- The current implementation of JURA and A-REX supports only one expiration time for all the reporting destinations. Even though the configuration enables the specification of different expiration values per reporting destination, it is not taken into account by the system, the last value is used as the common expiration time value.
- It is not possible to use different credentials per destinations.
- If you are updating from ARC5 with an old jura accounting archive already containing records, the conversion process to index the archive structure will be initiated and will cause serious system load until finished. To avoid old archive conversion, you can move records before update.
- Some optional UR properties are not supported.
- Memory can be reported incorrectly with buggy GNU “time” results.
Definition of the A-REX Accounting Record including JURA attribute mappings to SGAS and APEL¶
| A-REX Accounting Record (AAR) | SGAS OGF-UR | APEL CAR | Content description |
|---|---|---|---|
| ngjobid | RecordIdentity is composed of ngjobid and hostname taken from the headnode. |
RecordIdentity is composed of ngjobid and hostname taken from the headnode. |
The global unique jobid assigned by AREX. |
| globalid | JobIdentity.GlobalJobId |
JobIdentity.GlobalJobId |
The global unique jobid assigned by AREX. For gridftp inteface it contains full URL. |
| localid | JobIdentity.LocalJobId |
JobIdentity.LocalJobId |
LRMS job ID |
| jobname | JobName |
JobName |
User specified job name |
| headnode | MachineName |
MachineName, SubmitHost, Site |
The A-REX job submission endpoint URL used for this job |
| lrms | not used | Infrastructure (used as a part of it) |
The LRMS behind A-REX |
| queue | Queue |
Queue |
The name of the LRMS queue of the job |
| nodename | Host |
Host |
WN name(s) as given by LRMS separated by : |
| clienthost | SubmitHost (port removed) |
not used | Client connection socket from the client to A-REX |
| usersn | UserIdentity.GobalUserName |
UserIdentity.GobalUserName |
The global user identity, at the moment it is the SN from the certificate |
| localuser | UserIdentity.LocalUserId |
UserIdentity.LocalUserId |
The mapped local userid |
| usercert | UserIdentity.VO and child structures |
UserIdentity.Group and UserIdentity.GroupAttribute |
contains the full proxy cert chain |
| projectname | ProjectName |
UserIdentity.GroupAttribute |
User-defined name of the project the job belongs to |
| status | Status |
Status |
The terminal state of an A-REX job: aborted, failed, completed |
| exitcode | not used | ExitStatus |
The exit code of the payload in the LRMS |
| submissiontime | StartTime |
StartTime |
The timestamp of job acceptance at A-REX |
| endtime | EndTime |
EndTime |
The timestamp when the job reached the terminal state in A-REX |
| nodecount | NodeCount |
NodeCount |
Number of allocated worker nodes |
| inputfile | FileTransfers |
not used | Details of downloaded inputfile: url, size, transfer start, transfer end, downloaded from cache |
| outputfile | FileTransfers |
not used | Details of uploaded outputtfile: url, size, transfer start, transfer end |
| usedmemory | Memory |
Memory |
Maximum virtual memory used by the job |
| usedmaxresident | Memory |
Memory |
Maximum resident memory used by the job |
| usedaverageresident | Memory |
Memory |
To be dropped from the AAR schema |
| usedwalltime | WallDuration |
WallDuration |
The measured clocktime ellapsed during the execution of the job in the LRMS. No matter on how many cores, processors, nodes the user job ran on. |
| usedcputime | CpuDuration |
CpuDuration (with type all) |
The total CPU time consumed by the job. If the job ran on many cores/processors/nodes, all separate consumptions shall be aggregated in this value. |
| usedusercputime | CpuDuration (with type user but should not be there) |
CpuDuration (with type user) |
The user part of the usedcputime |
| usedkernelcputime | CpuDuration (with type system but should not be there) |
CpuDuration (with type system) |
The kernel part of the usedcputime |
| A-REX Accounting Record (AAR) | SGAS OGF-UR | APEL CAR | Content description |
|---|---|---|---|
| cores | Processors |
Processors |
The number of cores allocated to the job |
| systemsoftware | The type and version of the system software (i.e. opsys, glibc, compiler, or the entire container wrapping the system software) | ||
| WNinstance | ServiceLevel |
Coarse-grain characterization tag for the WorkerNode, e.g. BigMemory or t2.micro (aka Amazon instance type) | |
| RTEs | List of used RTEs, including default ones as well. | ||
| data-stagein-volume | Network class has something similar |
The total volume of downloaded job input data in GBs | |
| data-stagein-time | The time spent by the DTR sysem to download input data for the job | ||
| data-stageout-volume | Network class has something similar |
The total volume of uploaded job output data in GBs | |
| data-stageout-time | The time spent by the DTR sysem to upload output data of the job | ||
| lrms-submissiont-time | The timestamp when the job was handed over to the LRMS system | ||
| lrmstarttime | The timestamp when the payload starts in the LRMS | ||
| lrmsendtime | The timestamp when the payload completed in the LRMS | ||
| authtokenattributes | UserIdentity.VO and child structures |
UserIdentity.Group and UserIdentity.GroupAttribute |
to be implemented to store e.g. VO atributes and simillar capabilities |
| submissioninterface | to be implemented, at the same time clean up globalid that depends on submissioninterface type | ||
| benchmark | Benchmark |
ServiceLevel |
The type and the corresponding benchmark value of the assigned WN |
| usedscratchspace | StorageUsageBlock |
The used size of scratch dir at the end of the job termination in the LRMS. |
| SGAS OGF-UR | APEL CAR |
|---|---|
ProcessID |
|
Charge |
Charge |
Swap |
Swap |